Python script pro
This type of data source can be used in a processing pipeline in OVITO to run a user-defined Python function generating the input dataset for the pipeline. It is an alternative to the standard file-based data source of OVITO, which loads the input data from a simulation file stored on disk.
You can insert a new data pipeline with a Python script data source into the scene using the pipeline selector widget located in the toolbar of OVITO.
What is a Python data source?
A Python-based data source consists of the definition of a Python function, which you enter into the integrated code editor window. Here is a simple example of such a function:
def create(frame, data):
cell_matrix = [[10,0,0,0],[0,10,0,0],[0,0,10,0]]
data.create_cell(cell_matrix, pbc=(False, False, False))
This example function calls create_cell() to set up a SimulationCell object, placing it into
the DataCollection container provided by the system.
The pipeline system of OVITO will run that Python function
whenever needed in order to generate the data objects that flow down the pipeline. Any subsequent modifiers
you insert into the pipeline will see these data objects. And eventually,
the final pipeline output will appear in the interactive viewports of OVITO.
Capabilities
The Python data source gives you a way to generate ad-hoc contents within OVITO, for example, a molecular structure constructed by an algorithm you write in Python. It frees you from having to prepare these contents outside of OVITO, using for example a simulation code or external model building tool, and then importing them into OVITO using the regular file import function (creating a file-based data source).
Within the create() function you define, you have a lot of freedom in building a new dataset and which
kinds of data objects you create. You can add a simulation cell, particles, bonds, global attributes, surface meshes,
and any other type of data object OVITO supports. Furthermore, you can define function parameters in your create() function,
which will be exposed in the user interface of OVITO (see below). You can interactively adjust the values of these parameters, and the pipeline system
will automatically re-run your function to update the results.
Further applications
A Python-based data source may be used to implement a simple kind of file reader for data file formats not
directly supported by OVITO. Then your create() function is responsible for opening and parsing the
data file using Python’s I/O facilities. The data read from the input file must be translated into corresponding
calls to OVITO’s Python API for creating new data objects such as particles.
Requirements
The user-defined create() function must fulfill the following requirements:
It must accept at least the following two parameters:
- frame:
An integer indicating the current animation frame (zero-based) at which the pipeline system evaluates the data source. By incorporating this value in your algorithm, you can implement data sources that produce time-dependent content or trajectories.
- data:
A
DataCollectionobject provided by the pipeline system, which should be populated with data objects by the function.
The DataCollection passed into the function by the pipeline system will initially be empty (when the function is
run for the first time). Your code should populate it with new data objects, typically by appending them to the DataCollection.objects list
or by assigning them directly to specific storage fields such as the cell field as in the example above.
However, there is one important caveat to prepare for: The system may run your create() function multiple times, and on subsequent invocations,
the DataCollection won’t be empty anymore. It will contain the data objects from a previous invocation. That’s because the pipeline system
maintains a data cache to allow the user to directly manipulate some of the objects in the graphical user interface of OVITO,
for example the colors and radii of particles types or the settings of visual elements associated with data objects.
That is an aspect your create() function needs to be prepared for. It must re-use any existing data objects in the data collection instead
of recreating them during each execution in order to preserve the adjustments the user makes to these objects in the GUI. In the code example above,
the function first checks if the data collection already contains an existing SimulationCell and creates a new one only if
this is not the case. The same kind of existence check should be performed when creating particles, bonds, particle types, etc.:
# Create the Particles data object only if it does not already exist from a previous run:
if not data.particles:
data.particles = Particles(vis = ParticlesVis(scaling = 0.5))
Resizing the Particles property container or adding properties can be performed without a
check because these operations preserve existing object instances instead of completely replacing them:
data.particles_.count = 3
data.particles_.create_property('Position', data=[(-0.06, 1.83, 0.81),(1.79, -0.88, -0.11),(-1.73, -0.77, -0.61)])
But make sure you do not accidentally recreate nested sub-objects, for example, the ParticleType instances
that are added to the Particle Type property. Only on the first run the Property.types list
will be empty:
type_property = data.particles_.create_property('Particle Type')
if len(type_property.types) == 0:
type_property.types.append(ParticleType(id=1, name='Cu', color=(1,1,0)))
type_property.types.append(ParticleType(id=2, name='O', color=(1,0,0)))
In the GUI, you can explicitly reset the data source’s cached data collection and discard all
cached data objects by pressing the button Reset data collection. The pipeline system will then start over
by invoking your create() function with an empty data collection, and all data objects are newly created and
initialized. Any changes the user has made to the old data objects in the GUI will be thrown away. (Applied modifiers will
be preserved, of course, because the reset operation only affects the source of the pipeline.)
User-defined function parameters
Your create() function may define additional keyword parameters (all require initial default values), which will be treated as user-defined
parameters managed by the data source. The user-defined parameters automatically appear in the graphical user interface of OVITO, and their
values (which will be passed to create() by the system) can be adjusted interactively by the user. For example:
def create(frame, data, width = 1.0, length = 1.0, height = 1.0):
if not data.cell: data.cell = SimulationCell()
data.cell_[:,:3] = [[width,0,0], [0,length,0], [0,0,height]]
Note that the default arguments defined in the function header only specify the initial values of the parameters
and their data types. In the user interface you adjust the actual values of these parameters, which are in effect
when the create() function gets invoked by the system.
The current implementation supports user-defined parameters that are from one of the following type categories:
Numeric, Boolean and string value types,
Any type that can be turned into a string representation using the
repr()function of Python and parsed back to a Python value with theeval()function (e.g. the tuple(1.0, 2.0, 0.0)),Any object type from the OVITO module such as
ParticleTypeorClusterAnalysisModifier.
The GUI will present special input controls for parameters from the first category, for example a check box widget for Boolean function parameters.
Parameter values from the second category must be entered by the user as Python literal expressions.
The native OVITO objects associated with function parameters from the third category will appear
as extra panels in the GUI, which will let you edit the attributes of these objects directly. The VectorVis
element shown in the following screenshot is an example of such a user-defined parameter:
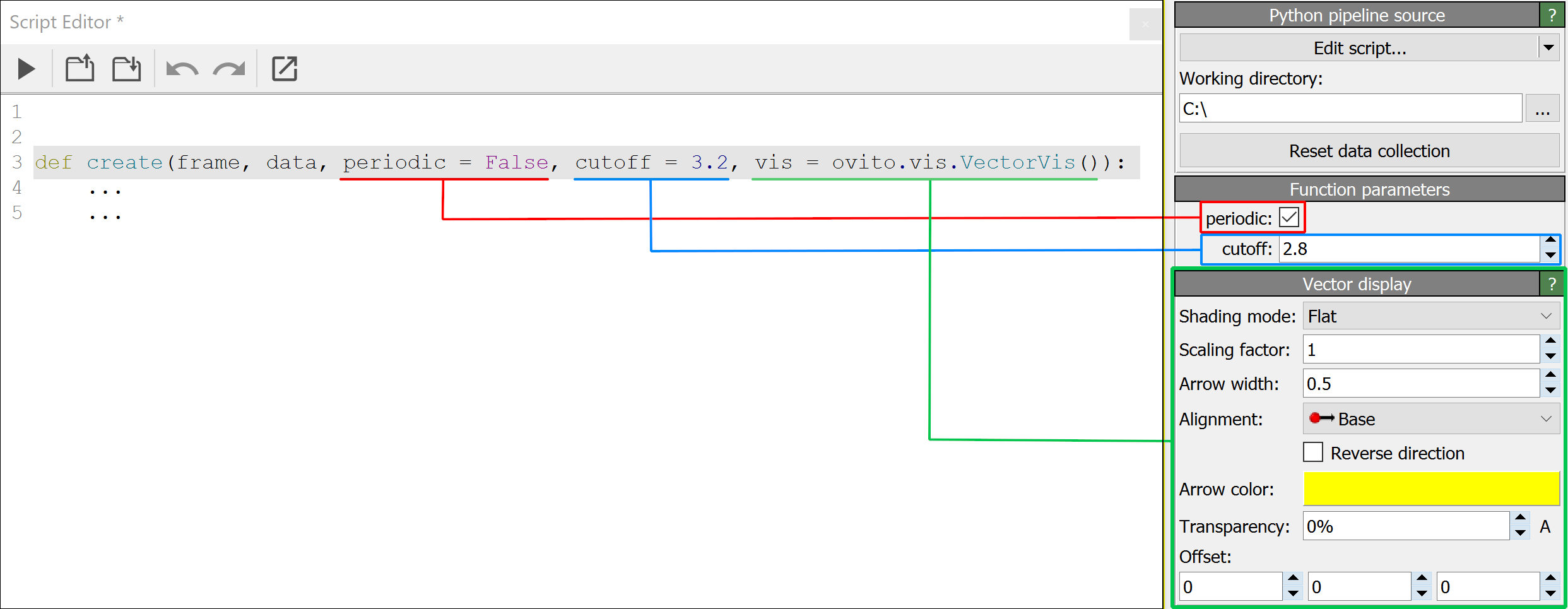
See also
ovito.pipeline.PythonSource(Python API)ovito.pipeline.PipelineSourceInterface(Python API)